
1. xRecorder:语音语料库录制工具
作者:熊子瑜
工具ID:Tools.XZY20211116.001
更新时间:2021年11月16日
简介:语音语料库录制工具 xRecorder 程序由熊子瑜设计开发,属于 xSpeechTools 工具的一个子程序,主要面向语音语料库建设中的录音任务,支持 wav 格式的音频文件录制、播放与声学参数分析显示。主要功能包括:(1)程序支持用户自由定制发音文本内容及其声音文件名(可使用多层级相对路径),基本能够满足有发音底稿的语音库录制需求,特别适用于字、词、句材料的大规模录音任务。(2)程序可按照固定或随机的顺序逐条显示发音文本,并按照用户设定的路径和文件名自动保存录制好的声音文件(*.wav)及其相应的发音文本内容(*.txt)。(3)程序支持用户逐条设置各类发音提示,如提示文本、提示声音(*.wav)或提示图片(*.jpg)等。(4)程序可检测全局最大振幅和首尾段的最大振幅,全局最大振幅如果大于或小于设定的阈值则会自动报错并强制重新录音,首尾段的最大振幅如果大于设定的阈值则会自动报错并强制重新录音,可有效避免振幅过大或过弱,还可避免非正常截断等类型的错误数据。(5)程序可实时显示波形图和宽带语图,有利于用户掌控发音进程,还可以缩放显示波形图和语图,并可以分析选定段的音高数据。(6)程序支持用户对发音文本内容的编辑修改和自动保存。(7)程序支持用户截取保存声音片段,或剪切掉噪声段数据,对声音进行整理。(8)每次重启程序,会自动定位至第一个未录制的条目,以避免出现条目遗漏。
2. xSegmenter:音段自动切分与标注工具
作者:熊子瑜
工具ID:Tools.XZY20211116.002
更新时间:2017年1月10日
简介:xSegmenter采用Perl脚本语言编写,主要面向较大规模的具有文字底稿的语音语料库建设,旨在解决音段标注的效率和一致性问题。该程序通过调用HTK工具,基于用户所提供的语料及相关资源训练生成HMM声学模型,然后进行音段强制对齐,最后针对每个声音文件转写生成相应的语音标注文件(*.TextGrid),包括文本层、词语层、音节层和音素层等标注内容。由于该工具自身不提供任何声学模型和词典,而是基于用户所提供的声音文件,带有分词信息的发音文本文件和发音词典文件等数据资源自动训练生成相应的语音声学模型,然后再利用所生成的语音声学模型去完成音段的自动切分和标注任务,因此这一工具可适用于任意语言和方言的语音库建设。
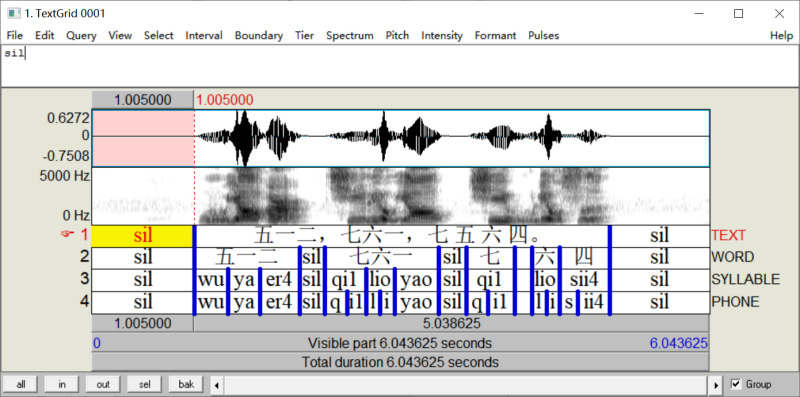
自动切分与标注结果示例
3. xPerception:语音感知实验工具
作者:熊子瑜
工具ID:Tools.XZY20211116.003
更新时间:2021年11月16日
简介:该工具能够记录被试操作的按键名称,还可以记录用户对各个声音文件的操作反应时间,能够基本满足语音感知实验的数据采集要求,既可用于语音感知实验,也可用于语音训练。程序可支持文字和图片两种格式的提示内容,除了可记录用户的按键操作外,也可记录用户在电脑屏幕上的点击操作。程序启动之后,会首先显示引导页内容信息,然后等被试按“空格键”后开始语音感知实验过程。此程序会以随机或者顺序的模式播放指定文件夹(可包含测试声音文件夹和训练声音文件夹)或数据表中给出的全部声音文件,并记录用户的按键名称和反应时,即被试的按键时间与声音播放起始时间点、或声音播放结束时间点、或提示信息显示出来的时间点之间的时间差,单位为毫秒。结果数据会保存在测试用的声音文件夹之中,或者与数据表文件保存在同一个文件夹之中。另外,此程序会自动检测上次听辨过程是否完全结束,并提示用户是否继续执行未完成的听辨过程,因此用户可以随时关闭或重启听辨程序。此程序还允许用户执行多次听辨过程(听完所有声音文件为一次完整听辨过程),其结果文件会分别采用1、2、3、4等序号加以区别,每次退出程序时会自动保存数据。

xPerception 程序运行界面示例(点击操作)

xPerception 程序运行界面示例(按键操作)