
1. 批量生成汉字的图片文件
作者:熊子瑜
脚本ID:Praat.XZY20210904.001
上传时间:2021年9月4日
简介:该脚本可控制图片大小、汉字大小、汉字颜色(红、蓝、黑、绿、黄),一个字一张图片,批量生成,自动保存至指定的文件夹之中。
2. 批量生成各类声学参数文件
作者:熊子瑜
脚本ID:Praat.XZY20210904.002
上传时间:2021年9月4日
简介:该脚本根据用户指定的声音文件路径或声音文件名列表,自动生成各类声学参数数据对象文件,目前包括PitchTier、IntensityTier、FormantGrid 三种类型,此脚本适用于任意声音文件。该脚本可配置发音人的音域范围、共振峰上限频率等参数,对于双通道的声音文件,可由用户指定某特定通道数据进行分析。批量生成的各类声学参数文件会被自动保存至声音文件所在的目录之中。
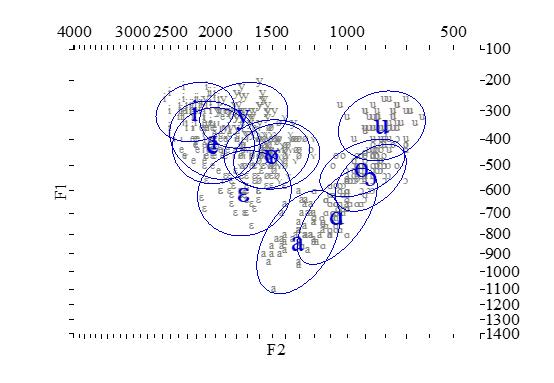
3.元音散点椭圆作图脚本
作者:凌锋
脚本ID:Praat.LF20210904.003
上传时间:2021年9月4日
简介:用praat画声学元音图,首先需要准备一个共振峰数据文件。可以先以praat内置的荷兰语元音数据为例,在Praat主窗口依次点击 new –> tables –> creat tableofreal(pols 1973),可生成这样一个数据文件。生成之后,点击Save菜单下的Save as headerless spreadsheet file按钮即可保存这个数据文件。这是一个纯文本的文件,改一下里面相关参数和数据就可以生成自己的共振峰文件。点击 Open 菜单下的Read TableOfReal from headerless spreadsheet file 可打开自己的数据表。然后选定数据表对象,就可以采用此脚本来画声学元音图了。请注意,其中optionmenu biankuang (是否清空后画边框)的作用有两个,一个是清空作图区域,另一个是画出边框,所以如果要再叠加其他数据图形,biankuang就要选择no。作图效果大致如下所示,该脚本还支持添加椭圆,更改颜色,改变字符大小等操作。
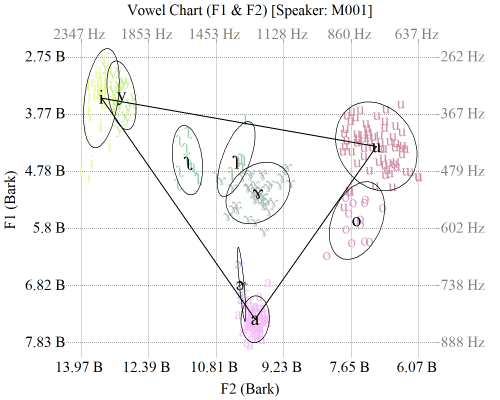
4.声学元音图制作脚本
作者:熊子瑜
脚本ID:Praat.XZY20210905.004
上传时间:2021年9月5日
简介:该脚本程序可根据用户给定的元音共振峰数据表,制作生成声学元音图(散点图+椭圆)。元音共振峰数据表的制作格式可参考“声学元音图数据.txt”,为UTF-8编码格式的纯文本文件,包含4列数据,第一列为序号信息,第二列为单元音,第三和第四列分别为F1和F2数据,这4列数据的标题默认为“序号、元音、F1、F2”,各列数据用制表符分隔。作图效果大致如下所示,该脚本可支持用户自定义图片大小、图例标题、刻度单位、刻度范围等,还可以根据用户设定的标准差范围自动剔除一些奇异值。
5.顺序检校TextGrid和PitchTier数据对象
作者:熊子瑜
脚本ID:Praat.XZY20210905.005
上传时间:2021年9月5日
简介:该脚本用于顺序打开指定文件夹中的WAV、TextGrid和PitchTier等数据文件,并等待用户手工修改之后点击“前进、后退、结束”等按钮,以控制标注检校流程,脚本程序会自动保存当前数据文件,并读取出下一条数据文件。结束时请点击“结束”按钮。脚本程序会在声音文件夹中保存一个名为done.log的文本文件,用于记录操作的文件序号,如果删除,则会重头开始计数。另外,此脚本在运行过程中会调用winPosition.exe程序,用于控制TextGrid和PitchTier编辑窗口的显示位置,以便于用户标注等操作,该程序由笔者编写,可放心使用。
6.VC时长指标的分析与提取脚本
作者:邵鹏飞
脚本ID:Praat.SHPF20210905.006
上传时间:2021年9月5日
简介:在韵律研究中,有学者使用 V、C时长参数来描述节奏,V指元音,C指辅音。此脚本程序可基于TextGrid文件提取以下参数:(1)sum_V:所有V的时长总和;(2)sum_C:所有C的时长总和;(3)mean_V:所有V的时长平均值;(4)mean_C:所有C的时长平均值;(5)delta_V:所有V的时长方差(standard deviation);(6)delta_C:所有C的时长方差(standard deviation);(7)percent_V:所有V占的百分比;(8)varco_V=100*(delta_V/mean_V), 是用方差除以平均值。有些论文里称为变异指数;(9)varco_C=100*(delta_C/mean_C), 有些论文里称为变异指数;(10)PVI叫做Pairwise Variability Index,把当前这个V或者C的时长和下一个V或者C的时长差都计算出来,再把这些差进行平均。(更多信息请参看:原文链接)
参考文献:Gibbon, Dafydd, and Ulrike Gut. “Measuring speech rhythm.” Seventh European Conference on Speech Communication and Technology. 2001.
7.标注数据和声学参数提取
作者:熊子瑜
脚本ID:Praat.XZY20210905.007
上传时间:2021年9月5日
简介:此脚本用于提取汉语语音材料的标注数据和相应的声学参数,按每个音节的韵母段等间隔提取10个或N个声学参量,还可以基于音节中心点的时间信息,提取其他比音节层更高的层级标注数据。如果标记中含有音高特征点或共振峰特征点,且一个韵母内部大于1个特征点,则会用特征点数据替换该韵母段的原始声学数据,特征点之间会通过插值方式来处理。数据基本要求:(1)TextGrid和声学参数文件(PitchTier、IntensityTier或FormantGrid)需成对出现在同一文件夹之中,除了文件扩展名不同,其余部分均应完全相同。(2)TextGrid中至少应该包含音节层标注和声韵母层标注,调类需采用“0、1、2、……、9”等数字标记在音节和韵母之后,儿化韵用“r”标记在音节或韵母之后(调类之前)。提取出来的数据结果文件会保存在指定的文件夹之中。
8.导入数据并自动生成TextGrid数据对象
作者:熊子瑜
脚本ID:Praat.XZY20210905.008
上传时间:2021年9月5日
简介:该脚本根据用户指定的路径下的发音文本文件(*.txt),自动生成相应的TextGrid标注文件。需要注意以下几点:(1)发音文本文件的扩展名必须为*.txt,如果有与之相对应的声音文件,则扩展名必须为*.wav,且必须与发音文本文件(*.txt)保存在相同文件夹之中。(2)发音文本文件必须使用UTF-8编码格式,所有的文本内容都应放在第一行。(3)在自动生成的TextGrid数据对象中,其音节和声韵母等边界的位置都是不准确的,需要手工校准。(4)脚本程序会自动读取发音文本文件,并按照一定的格式解析其内容,汉语发音文本建议采用半角空格分词,以便于后期提取词表制作发音词典用于音段自动切分。另外,除了发音内容之外,在发音文本内容后面的尖括号“<>”中可以包含需要自动导入至TextGrid中的标注数据,标注数据应遵循如下格式:各层级标注内容应按次序分别放到中括号“[]”之中,分别包含关键词和标注内容,二者之间用半角冒号分隔;关键词放在英文冒号之前,将用作标注层级名称,英文冒号之后为相应的标注内容,标注内容中可使用以下分隔符:半角空格用作词语分隔符,且应与发音文本中的词语分隔位置一致;“&”用作词内音节分隔符;“|”用作音节内的声韵分隔符;声调用“0、1、2、3、4、……、9”等数字标记在音节和韵母末尾;儿化韵用“r”标记在声调之前;拼音文本中的标点符号可用空格代替。发音文本的内容及其格式示例如下:
- 学<[拼音:x|ve2][古音:匣;觉;入;江;开;二;觉;全浊;见系;晓组][备注:学习;数学]>
- 学习<[拼音:x|ve2&x|i2]>
- 小 老虎 <[拼音:x|iao3 l|ao3&h|u3][类型:1+2][词类:形容词 名词]>
- 表演 者 <[拼音:b|iao3&yan3 zh|e3][类型:2+1][词类:动词 名词缀]>
- 洗 脸 水 <[拼音:x|i3 l|ian3 sh|ui3][类型:{1+1}+1][词类:动词 名词 名词]>
- 我 想要 学习 语音学 ,她 也 要 学习 语音学。<[拼音:wo3 x|iang3&yao4 x|ve2&x|i2 yu3&yin1&x|ve2 t|a1 ye3 yao4 x|ve2&x|i2 yu3&yin1&x|ve2]>
- 我 想要 学习 语音学。<强调“学习” [拼音:wo3 x|iang3&yao4 x|ve2&x|i2 yu3&yin1&x|ve2]>
9.声调连续统刺激音生成
作者:熊子瑜
脚本ID:Praat.XZY20210905.009
上传时间:2021年9月5日
简介:此脚本主要用于生成类似于下图所示的刺激音,用户可以控制起点、拐点和末点的音高值(Hz标度),可以控制音高段时长(秒),可以控制拐点在音高段的位置(百分比)。用户还可以控制音高数据是按半音标度等间距逼近,还是按照Hz标度等间距逼近。脚本程序会合成出相应的刺激音,用于辨认实验;还会按照用户设定的间隔步长和停顿时长拼合成ABX(具体包括ABA、ABB、BAA、BAB四种类型供选用)类型的听辨刺激音,用于区分实验。所有刺激音均是基于用户提供的基础声音文件调整其音高和时长等参数而成,会保存至用户提供的基础声音文件所在的文件夹之中。
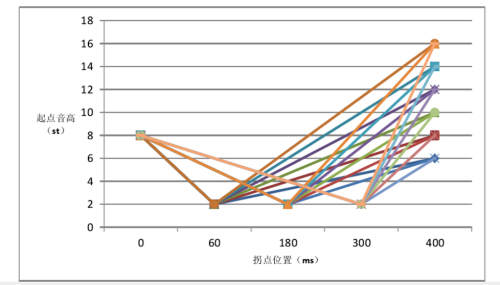
10.音高和时长等声学参数移植
作者:熊子瑜
脚本ID:Praat.XZY20210905.010
上传时间:2021年9月5日
简介:此脚本可用于替换修改声音文件的音高和/或时长数据,可以整句替换,也可以仅替换最后一个词,还可以指定特定词的Interval序号。使用时,用户需指定两个发音内容完全相同的声音文件,每个声音文件应有着相应的TextGrid标注文件,标注好词语、音节和音素等层级内容,声音文件与标注文件需存放在相同的目录之中。程序会按照Interval的先后顺序去替换音高和/或时长数据,因此要求两个TextGrid的对应层级具有相同的Interval个数,而且标注内容能够对齐。目前此脚本可替换音高和/或时长数据,如果能够顺利运行结束,将生成一个名为new的声音对象。
11.发声参数提取
作者:熊子瑜
脚本ID:Praat.XZY20210906.011
更新时间:2021年9月6日
简介:该脚本针对用户指定文件夹中的全部声音文件及其标注文件,测量出各音段成分的一系列发声参数:H1-H2, H1-A1, H1-A2 和H1-A3。基本要求:声音文件需配有相应的音段标注文件TextGrid,并需成对地存放在同一个文件夹之中。(此脚本修改自:原始脚本)
12.提取Pitch、Jitter、Shimmer和Harmonicity等参数
作者:熊子瑜
脚本ID:Praat.XZY20210906.012
上传时间:2021年9月6日
简介:此脚本可用于批量提取用户指定的文件夹中所有声音文件或声音文件中各个音段的Pitch、Jitter、Shimmer和Harmonicity等数据,只报告声音文件或特定声音片段中有基频数据部分的嗓音情况。此脚本是在冉启斌老师的脚本( 2019-06-25)的基础上修改完成的,主要增加了以下两个方面的功能:(1)可基于TextGrid标注文件,对每个音节或音段提取其嗓音数据。此时需将标注文件与声音文件放在同一目录之中。如果没有相应的标注文件,或者用户将脚本程序的控制参数Phone_Tier_Index设置为0,则会针对整个声音文件提取相应参数,这主要适用于汉语单音节语音文件的数据提取。(2)增加了更多的输出参数,Pitch部分包括Median pitch、Mean pitch、Standard deviation、Minimum pitch、Maximum pitch等5个参数,Jitter部分包括Jitter (local)、Jitter (rap)、Jitter (ppq5)、Jitter (ddp)等4个参数,Shimmer部分包括Shimmer (local)、Shimmer (local, dB)、Shimmer (apq3)、Shimmer (apq5)、Shimmer (apq11)、Shimmer (dda)等6个参数,Harmonicity部分包括Mean autocorrelation、Mean noise-to-harmonics ratio、Mean harmonics-to-noise ratio等3个参数。(此脚本修改自:原始脚本)
13.声音文件的规整处理
作者:熊子瑜
脚本ID:Praat.XZY20210907.013
上传时间:2021年9月7日
简介:此脚本可针对用户指定的声音文件夹,对全部声音文件进行如下一项或多项规整处理,并保存至另一个文件夹之中:(1)从双通道声音文件中提取并保存指定通道的声音数据;(2)对声音文件按照用户设定的频率进行重新采样;(3)给每个声音文件增加一些随机噪音成分,仅针对单通道声音文件;(4)截去声音文件起始和结束部分多余的空白时长;(5)规整声音文件的音强平均值;(6)规整声音文件的最大幅度值。
14.基于TextGrid标注内容截取声音及标注片段
作者:熊子瑜
脚本ID:Praat.XZY20210907.014
上传时间:2021年9月7日
简介:根据用户指定的声音文件夹,针对其中的全部声音文件(*.wav),基于各个声音文件所对应的标注文件(*.TextGrid)中的标注内容和时间信息,将其截取成相应的声音片段,并另外保存起来,会同步截取保存标注片段的内容文件。使用时,每个声音文件需有相应的标注文件,并成对存放在相同的文件夹之中,另外用户需指定标注内容所在的层级序号。用户可设定不用截取保存的标注内容,多个标签之间用“,”分隔。另外,标注层级中的空白部分(即无标注内容的片段)也会被脚本程序自动忽略,不做截取保存。此脚本程序适用于较多字词条目的长录音文件的截取保存操作。
15.提取与音强相关的声学参数
作者:熊子瑜
脚本ID:Praat.XZY20210908.015
上传时间:2021年9月8日
简介:针对用户指定的某个文件夹中的全部声音文件,按其标注文件中的音段时间信息分别提取下列与音强相关的几项声学参数:(1)基于Sound数据对象提取Mean,Root-mean-square,Standard deviation;Energy,Power,Energy in air,Power in air,Intensity(dB)等声学参数;(2)基于Intensity数据对象提取音强均值数据(分别采用dB、energy、sones等3种分析方法)。注意:标注文件必须与声音文件放在同一文件夹之中。
16.Praat基础脚本集
作者:赵彤
脚本ID:Praat.ZHT20210912.016
上传时间:2021年9月12日
简介:这套Praat脚本程序由赵彤老师编写和分享,内含较为详细的使用说明文件,并配有一些可供调用的数据文件,是一份非常不错的学习参考材料,共计包含16个Praat脚本程序,具体如下:(1)生成TextGrid文件;(2)截取声音和TextGrid文件;(3)截取声音和TextGrid文件映射定义新文件名;(4)生成声音数据文件;(5)提取单元音共振峰数据;(6)提取二合元音共振峰数据;(7)提取三合元音共振峰数据;(8)增加标注层;(9)删除标注层;(10)复制标注层;(11)修改标注名;(12)映射填写声韵母;(13)复制标注层并映射填写标注内容;(14)映射替换标注内容;(15)提取某个韵母的共振峰数据;(16)映射替换文件名。另外,再奉上赵彤老师编写的国际音标输入法,欢迎大家使用和分享。
17.提取声音文件的谐噪比及标准差数据
作者:冉启斌
脚本ID:Praat.RQB20210912.017
上传时间:2021年9月12日
简介:此脚本可针对用户指定的一个目录,提取该目录下所有文件夹中的声音文件的谐噪比(HNR)及其标准差数据(针对整个声音文件),并将全部数据结果存储成一个文本文件。
18.批量测算声音之间的DTW距离
作者:冉启斌
脚本ID:Praat.RQB20210912.018
上传时间:2021年9月12日
简介:此脚本可用于比较不同声音之间的DTW距离,直接用Sound文件求距离,不转为MFCC,并将所有距离数据存储为一个文本文件。 如一个词有多种说法,多种说法之间也可以比较。文件压缩包中含有4个脚本程序,使用者可根据需要选用或加以适当改编以适用于自己的数据集。
19.Praat 语音软件使用手册中的部分脚本
作者:熊子瑜
脚本ID:Praat.XZY20210917.019
上传时间:2021年9月17日
简介:重新整理和改写了《Praat 语音软件使用手册》中的几个脚本程序,具体包括:(1)提取二维频谱中某个频率位置的能量值;(2)提取二维频谱中前 n 个谐波峰的能量值;(3)提取二维频谱中各频率成分的能量值;(4)将共振峰频率数据提取到 TextGrid 对象中;(5)将 TextGrid 对象中的共振峰数据转换成文本文件。该手册中的其他一些脚本均已有新的版本,可在前文找到相关内容。
20.单字调音高数据均值分析并作图
作者:熊子瑜
脚本ID:Praat.XZY20211008.020
上传时间:2021年10月08日
简介:此脚本可基于音高数据文件(allData_PitchTier.txt)自动测算并绘制出单字调音高数据图,结果大致如下所示(作图区域大小由用户提前圈定),并将给出各个点的均值及标准差等数据。注意,此脚本仅适用于单个发音人的音高数据,每次针对一位发音人的数据进行操作。除了可直接使用Hz标度外,还支持 Mel、Erb、Bark、Log、SemiTone、Log z-score 等几种音高换算和规整方式。

21.音高数据提取与发音人音域范围测算
作者:熊子瑜
脚本ID:Praat.XZY20211214.021
上传时间:2021年12月14日
简介:此脚本可针对用户所指定的某个声音文件夹(全路径,以“\”结束),对每个声音文件所对应的PitchTier文件或Pitch文件进行分析(PitchTier文件优先,其次是Pitch文件),从这些音高数据文件中提取出全部音高数据,并据此测算出发音人的音高基本数据(如均值、标准差等)。如果某个声音文件没有相应的PitchTier文件和Pitch文件,则会自动提取生成相应的Pitch和PitchTier文件。脚本程序还会绘制出音高数据的频数分布图,以帮助用户确定发音人的音域范围,从而提取出更为精准的音高数据。
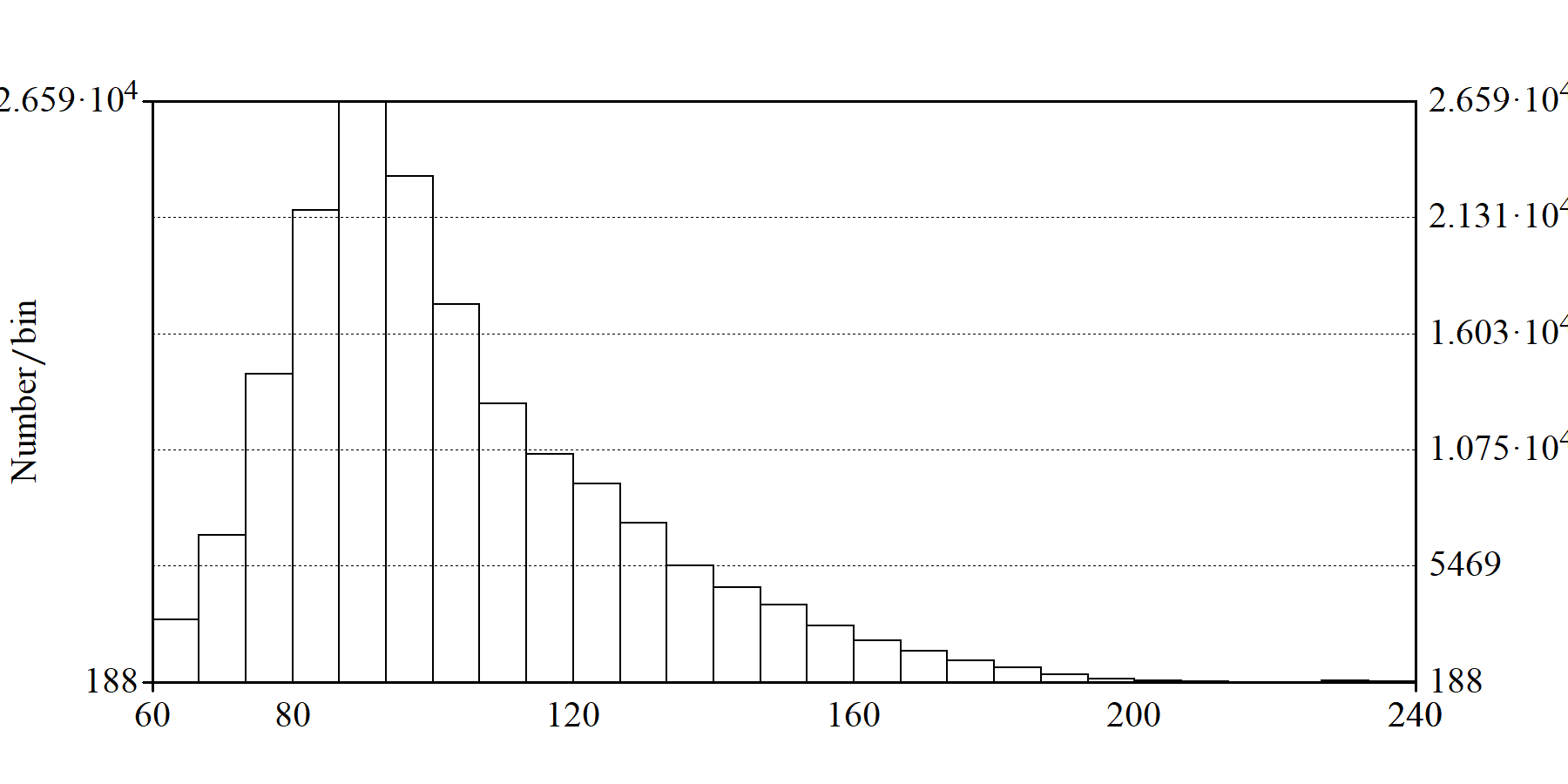
图:脚本程序制作的音高数据频数分布图
22.不同发音人的音高数据规整与对比
作者:熊子瑜
脚本ID:Praat.XZY20220102.022
上传时间:2022年01月02日
简介:不同人朗读同一篇语料,其韵律节奏模式可能会存在一定差异,音节时长和停顿模式有时会有较大差别,在Praat程序的编辑窗口中很难直接对比观察较长片段的语音音高数据。为便于将不同发音人的音高数据放在一起进行比较,笔者设计并开发了此脚本程序,可针对不同发音人的音高数据进行时长和频率两个维度的规整处理,然后将二者放在一起作图展示。此脚本可适用于较长的篇章语料分析,用户需事先要做好音节标注。
23.三阶音高赋值与音高拟合
作者:熊子瑜
脚本ID:Praat.XZY20220105.023
上传时间:2022年01月05日
简介:基于用户指定的一个 PitchTier 文件及相应的参数,自动生成一个由 H/M/L 三度音高拟合的音高数据对象,具体过程如下,首先将 PitchTier 进行 Stylize 处理,得到一个名为 ORI 的音高数据对象,然后在此基础上进行 Generalize 处理,得到一个名为 NEW 的音高数据对象。脚本程序会分析给出拟合的音高数据与原始的音高数据之间的相关系数和残差等数据,还会制作出一个重叠在一起的音高数据图,以便于观测音高数据拟合结果。另外,脚本程序还可以把三阶音高赋值结果写到相应的 TextGrid 文件之中。下图展示了脚本程序的三阶音高赋值结果,图中灰色的为原始音高数据,黄色为 Stylize 之后的音高数据,蓝色为 Generalize 之后的音高数据。

(持续更新中,欢迎大家分享自己的得意之作…)
更多Praat脚本程序请访问:
- 冉启斌老师整理和编写的脚本程序:
http://www.globalaccentchinese.com/soft.php
- 邵鹏飞老师编写的脚本程序:
https://blog.csdn.net/shaopengfei
- UCLA 网站上的脚本程序:
http://phonetics.linguistics.ucla.edu/facilities/acoustic/praat.html